
Contingency tables¶
Statsmodels supports a variety of approaches for analyzing contingency tables, including methods for assessing independence, symmetry, homogeneity, and methods for working with collections of tables from a stratified population.
The methods described here are mainly for two-way tables. Multi-way
tables can be analyzed using log-linear models. Statsmodels does not
currently have a dedicated API for loglinear modeling, but Poisson
regression in statsmodels.genmod.GLM can be used for this
purpose.
A contingency table is a multi-way table that describes a data set in
which each observation belongs to one category for each of several
variables. For example, if there are two variables, one with
 levels and one with
levels and one with  levels, then we have a
levels, then we have a
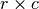 contingency table. The table can be described in
terms of the number of observations that fall into a given cell of the
table, e.g.
contingency table. The table can be described in
terms of the number of observations that fall into a given cell of the
table, e.g. 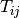 is the number of observations that have
level
is the number of observations that have
level 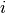 for the first variable and level
for the first variable and level 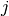 for the
second variable. Note that each variable must have a finite number of
levels (or categories), which can be either ordered or unordered. In
different contexts, the variables defining the axes of a contingency
table may be called categorical variables or factor variables.
They may be either nominal (if their levels are unordered) or
ordinal (if their levels are ordered).
for the
second variable. Note that each variable must have a finite number of
levels (or categories), which can be either ordered or unordered. In
different contexts, the variables defining the axes of a contingency
table may be called categorical variables or factor variables.
They may be either nominal (if their levels are unordered) or
ordinal (if their levels are ordered).
The underlying population for a contingency table is described by a
distribution table 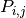 . The elements of
. The elements of 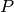 are probabilities, and the sum of all elements in is 1.
Methods for analyzing contingency tables use the data in
are probabilities, and the sum of all elements in is 1.
Methods for analyzing contingency tables use the data in 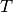 to
learn about properties of .
to
learn about properties of .
The statsmodels.stats.Table is the most basic class for
working with contingency tables. We can create a Table object
directly from any rectangular array-like object containing the
contingency table cell counts:
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: import statsmodels.api as sm
In [4]: df = sm.datasets.get_rdataset("Arthritis", "vcd").data
In [5]: tab = pd.crosstab(df['Treatment'], df['Improved'])
In [6]: tab = tab.loc[:, ["None", "Some", "Marked"]]
In [7]: table = sm.stats.Table(tab)
Alternatively, we can pass the raw data and let the Table class construct the array of cell counts for us:
In [8]: table = sm.stats.Table.from_data(df[["Treatment", "Improved"]])
Independence¶
Independence is the property that the row and column factors occur independently. Association is the lack of independence. If the joint distribution is independent, it can be written as the outer product of the row and column marginal distributions:

P_{ij} = sum_k P_{ij} cdot sum_k P_{kj} forall i, j
We can obtain the best-fitting independent distribution for our observed data, and then view residuals which identify particular cells that most strongly violate independence:
In [9]: print(table.table_orig)
Improved Marked None Some
Treatment
Placebo 7 29 7
Treated 21 13 7
In [10]: print(table.fittedvalues)
������������������������������������������������������������������������������������������������������������������������Improved Marked None Some
Treatment
Placebo 14.333333 21.5 7.166667
Treated 13.666667 20.5 6.833333
In [11]: print(table.resid_pearson)
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Improved Marked None Some
Treatment
Placebo -1.936992 1.617492 -0.062257
Treated 1.983673 -1.656473 0.063758
In this example, compared to a sample from a population in which the rows and columns are independent, we have too many observations in the placebo/no improvement and treatment/marked improvement cells, and too few observations in the placebo/marked improvement and treated/no improvement cells. This reflects the apparent benefits of the treatment.
If the rows and columns of a table are unordered (i.e. are nominal
factors), then the most common approach for formally assessing
independence is using Pearson’s 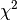 statistic. It’s often
useful to look at the cell-wise contributions to the
statistic to see where the evidence for dependence is coming from.
statistic. It’s often
useful to look at the cell-wise contributions to the
statistic to see where the evidence for dependence is coming from.
In [12]: rslt = table.test_nominal_association()
In [13]: print(rslt.pvalue)
0.00146264340895
In [14]: print(table.chi2_contribs)
�����������������Improved Marked None Some
Treatment
Placebo 3.751938 2.616279 0.003876
Treated 3.934959 2.743902 0.004065
For tables with ordered row and column factors, we can us the linear by linear association test to obtain more power against alternative hypotheses that respect the ordering. The test statistic for the linear by linear association test is
sum_k r_i c_j T_{ij}
where 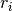 and
and 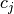 are row and column scores. Often
these scores are set to the sequences 0, 1, .... This gives the
‘Cochran-Armitage trend test’.
are row and column scores. Often
these scores are set to the sequences 0, 1, .... This gives the
‘Cochran-Armitage trend test’.
In [15]: rslt = table.test_ordinal_association()
In [16]: print(rslt.pvalue)
0.0236445780939
We can assess the association in a 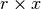 table by
constructing a series of
table by
constructing a series of 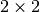 tables and calculating
their odds ratios. There are two ways to do this. The local odds
ratios construct tables from adjacent row and
column categories.
tables and calculating
their odds ratios. There are two ways to do this. The local odds
ratios construct tables from adjacent row and
column categories.
In [17]: print(table.local_oddsratios)
Improved Marked None Some
Treatment
Placebo 0.149425 2.230769 NaN
Treated NaN NaN NaN
In [18]: taloc = sm.stats.Table2x2(np.asarray([[7, 29], [21, 13]]))
In [19]: print(taloc.oddsratio)
0.149425287356
In [20]: taloc = sm.stats.Table2x2(np.asarray([[29, 7], [13, 7]]))
In [21]: print(taloc.oddsratio)
2.23076923077
The cumulative odds ratios construct tables by
dichotomizing the row and column factors at each possible point.
In [22]: print(table.cumulative_oddsratios)
Improved Marked None Some
Treatment
Placebo 0.185185 1.058824 NaN
Treated NaN NaN NaN
In [23]: tab1 = np.asarray([[7, 29 + 7], [21, 13 + 7]])
In [24]: tacum = sm.stats.Table2x2(tab1)
In [25]: print(tacum.oddsratio)
0.185185185185
In [26]: tab1 = np.asarray([[7 + 29, 7], [21 + 13, 7]])
In [27]: tacum = sm.stats.Table2x2(tab1)
In [28]: print(tacum.oddsratio)
1.05882352941
A mosaic plot is a graphical approach to informally assessing dependence in two-way tables.
from statsmodels.graphics.mosaicplot import mosaic
mosaic(data)
Symmetry and homogeneity¶
Symmetry is the property that 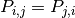 for
every and . Homogeneity is the property that
the marginal distribution of the row factor and the column factor are
identical, meaning that
for
every and . Homogeneity is the property that
the marginal distribution of the row factor and the column factor are
identical, meaning that
sum_j P_{ij} = sum_j P_{ji} forall i
Note that for these properties to be applicable the table
(and ) must be square, and the row and column categories must
be identical and must occur in the same order.
To illustrate, we load a data set, create a contingency table, and
calculate the row and column margins. The Table class
contains methods for analyzing contingency tables.
The data set loaded below contains assessments of visual acuity in
people’s left and right eyes. We first load the data and create a
contingency table.
In [29]: df = sm.datasets.get_rdataset("VisualAcuity", "vcd").data
In [30]: df = df.loc[df.gender == "female", :]
In [31]: tab = df.set_index(['left', 'right'])
In [32]: del tab["gender"]
In [33]: tab = tab.unstack()
In [34]: tab.columns = tab.columns.get_level_values(1)
In [35]: print(tab)
right 1 2 3 4
left
1 1520 234 117 36
2 266 1512 362 82
3 124 432 1772 179
4 66 78 205 492
Next we create a SquareTable object from the contingency
table.
In [36]: sqtab = sm.stats.SquareTable(tab)
In [37]: row, col = sqtab.marginal_probabilities
In [38]: print(row)
right
1 0.255049
2 0.297178
3 0.335295
4 0.112478
dtype: float64
In [39]: print(col)
�����������������������������������������������������������������������������right
1 0.264277
2 0.301725
3 0.328474
4 0.105524
dtype: float64
The summary method prints results for the symmetry and homogeneity
testing procedures.
In [40]: print(sqtab.summary())
Statistic P-value DF
--------------------------------
Symmetry 19.107 0.004 6
Homogeneity 11.957 0.008 3
--------------------------------
If we had the individual case records in a dataframe called data,
we could also perform the same analysis by passing the raw data using
the SquareTable.from_data class method.
sqtab = sm.stats.SquareTable.from_data(data[['left', 'right']])
print(sqtab.summary())
A single 2x2 table¶
Several methods for working with individual 2x2 tables are provided in
the sm.stats.Table2x2 class. The summary method displays
several measures of association between the rows and columns of the
table.
In [41]: table = np.asarray([[35, 21], [25, 58]])
In [42]: t22 = sm.stats.Table2x2(table)
In [43]: print(t22.summary())
Estimate SE LCB UCB p-value
-------------------------------------------------
Odds ratio 3.867 1.890 7.912 0.000
Log odds ratio 1.352 0.365 0.636 2.068 0.000
Risk ratio 2.075 0.636 2.068 0.000
Log risk ratio 0.730 0.197 0.345 1.115 0.000
-------------------------------------------------
Note that the risk ratio is not symmetric so different results will be obtained if the transposed table is analyzed.
In [44]: table = np.asarray([[35, 21], [25, 58]])
In [45]: t22 = sm.stats.Table2x2(table.T)
In [46]: print(t22.summary())
Estimate SE LCB UCB p-value
-------------------------------------------------
Odds ratio 3.867 1.890 7.912 0.000
Log odds ratio 1.352 0.365 0.636 2.068 0.000
Risk ratio 2.194 0.636 2.068 0.000
Log risk ratio 0.786 0.216 0.362 1.210 0.000
-------------------------------------------------
Stratified 2x2 tables¶
Stratification occurs when we have a collection of contingency tables
defined by the same row and column factors. In the example below, we
have a collection of 2x2 tables reflecting the joint distribution of
smoking and lung cancer in each of several regions of China. It is
possible that the tables all have a common odds ratio, even while the
marginal probabilities vary among the strata. The ‘Breslow-Day’
procedure tests whether the data are consistent with a common odds
ratio. It appears below as the Test of constant OR. The
Mantel-Haenszel procedure tests whether this common odds ratio is
equal to one. It appears below as the Test of OR=1. It is also
possible to estimate the common odds and risk ratios and obtain
confidence intervals for them. The summary method displays all of
these results. Individual results can be obtained from the class
methods and attributes.
In [47]: data = sm.datasets.china_smoking.load()
In [48]: mat = np.asarray(data.data)
In [49]: tables = [np.reshape(x, (2, 2)) for x in mat]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-49-023dddfffe37> in <module>()
----> 1 tables = [np.reshape(x, (2, 2)) for x in mat]
<ipython-input-49-023dddfffe37> in <listcomp>(.0)
----> 1 tables = [np.reshape(x, (2, 2)) for x in mat]
/private/tmp/statsmodels/.env/lib/python3.6/site-packages/numpy/core/fromnumeric.py in reshape(a, newshape, order)
230 [5, 6]])
231 """
--> 232 return _wrapfunc(a, 'reshape', newshape, order=order)
233
234
/private/tmp/statsmodels/.env/lib/python3.6/site-packages/numpy/core/fromnumeric.py in _wrapfunc(obj, method, *args, **kwds)
55 def _wrapfunc(obj, method, *args, **kwds):
56 try:
---> 57 return getattr(obj, method)(*args, **kwds)
58
59 # An AttributeError occurs if the object does not have
ValueError: cannot reshape array of size 1 into shape (2,2)
In [50]: st = sm.stats.StratifiedTable(tables)
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-50-eead6f66e108> in <module>()
----> 1 st = sm.stats.StratifiedTable(tables)
NameError: name 'tables' is not defined
In [51]: print(st.summary())
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-51-640262627808> in <module>()
----> 1 print(st.summary())
NameError: name 'st' is not defined
Module Reference¶
Table(table[, shift_zeros]) |
Analyses that can be performed on a two-way contingency table. |
Table2x2(table[, shift_zeros]) |
Analyses that can be performed on a 2x2 contingency table. |
SquareTable(table[, shift_zeros]) |
Methods for analyzing a square contingency table. |
StratifiedTable(tables[, shift_zeros]) |
Analyses for a collection of 2x2 contingency tables. |
mcnemar(table[, exact, correction]) |
McNemar test of homogeneity. |
cochrans_q(x[, return_object]) |
Cochran’s Q test for identical binomial proportions. |