
0.6 Release¶
Release 0.6.1¶
Statsmodels 0.6.1 is a bugfix release. All users are encouraged to upgrade to 0.6.1.
See the list of fixed issues for specific backported fixes.
Release 0.6.0¶
Statsmodels 0.6.0 is another large release. It is the result of the work of 37 authors over the last year and includes over 1500 commits. It contains many new features, improvements, and bug fixes detailed below.
See the list of fixed issues for specific closed issues.
The following major new features appear in this version.
Generalized Estimating Equations¶
Generalized Estimating Equations (GEE) provide an approach to handling dependent data in a regression analysis. Dependent data arise commonly in practice, such as in a longitudinal study where repeated observations are collected on subjects. GEE can be viewed as an extension of the generalized linear modeling (GLM) framework to the dependent data setting. The familiar GLM families such as the Gaussian, Poisson, and logistic families can be used to accommodate dependent variables with various distributions.
Here is an example of GEE Poisson regression in a data set with four count-type repeated measures per subject, and three explanatory covariates.
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
data = sm.datasets.get_rdataset("epil", "MASS").data
md = smf.gee("y ~ age + trt + base", "subject", data,
cov_struct=sm.cov_struct.Independence(),
family=sm.families.Poisson())
mdf = md.fit()
print mdf.summary()
The dependence structure in a GEE is treated as a nuisance parameter and is modeled in terms of a “working dependence structure”. The statsmodels GEE implementation currently includes five working dependence structures (independent, exchangeable, autoregressive, nested, and a global odds ratio for working with categorical data). Since the GEE estimates are not maximum likelihood estimates, alternative approaches to some common inference procedures have been developed. The statsmodels GEE implementation currently provides standard errors, Wald tests, score tests for arbitrary parameter contrasts, and estimates and tests for marginal effects. Several forms of standard errors are provided, including robust standard errors that are approximately correct even if the working dependence structure is misspecified.
Seasonality Plots¶
Adding functionality to look at seasonality in plots. Two new functions are sm.graphics.tsa.month_plot and sm.graphics.tsa.quarter_plot. Another function sm.graphics.tsa.seasonal_plot is available for power users.
import statsmodels.api as sm
import pandas as pd
dta = sm.datasets.elnino.load_pandas().data
dta['YEAR'] = dta.YEAR.astype(int).astype(str)
dta = dta.set_index('YEAR').T.unstack()
dates = map(lambda x : pd.datetools.parse('1 '+' '.join(x)),
dta.index.values)
dta.index = pd.DatetimeIndex(dates, freq='M')
fig = sm.tsa.graphics.month_plot(dta)
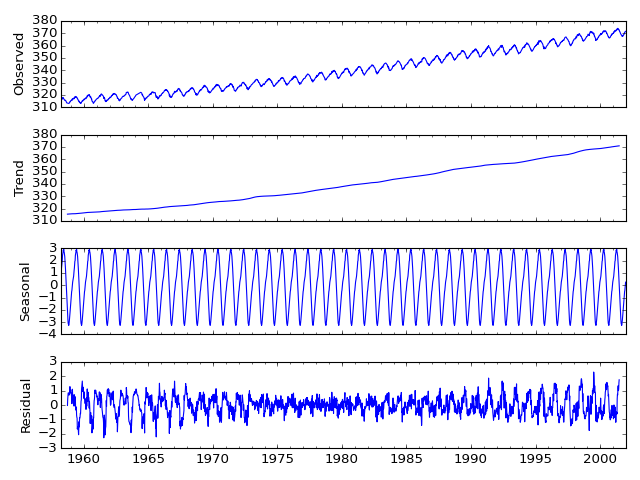
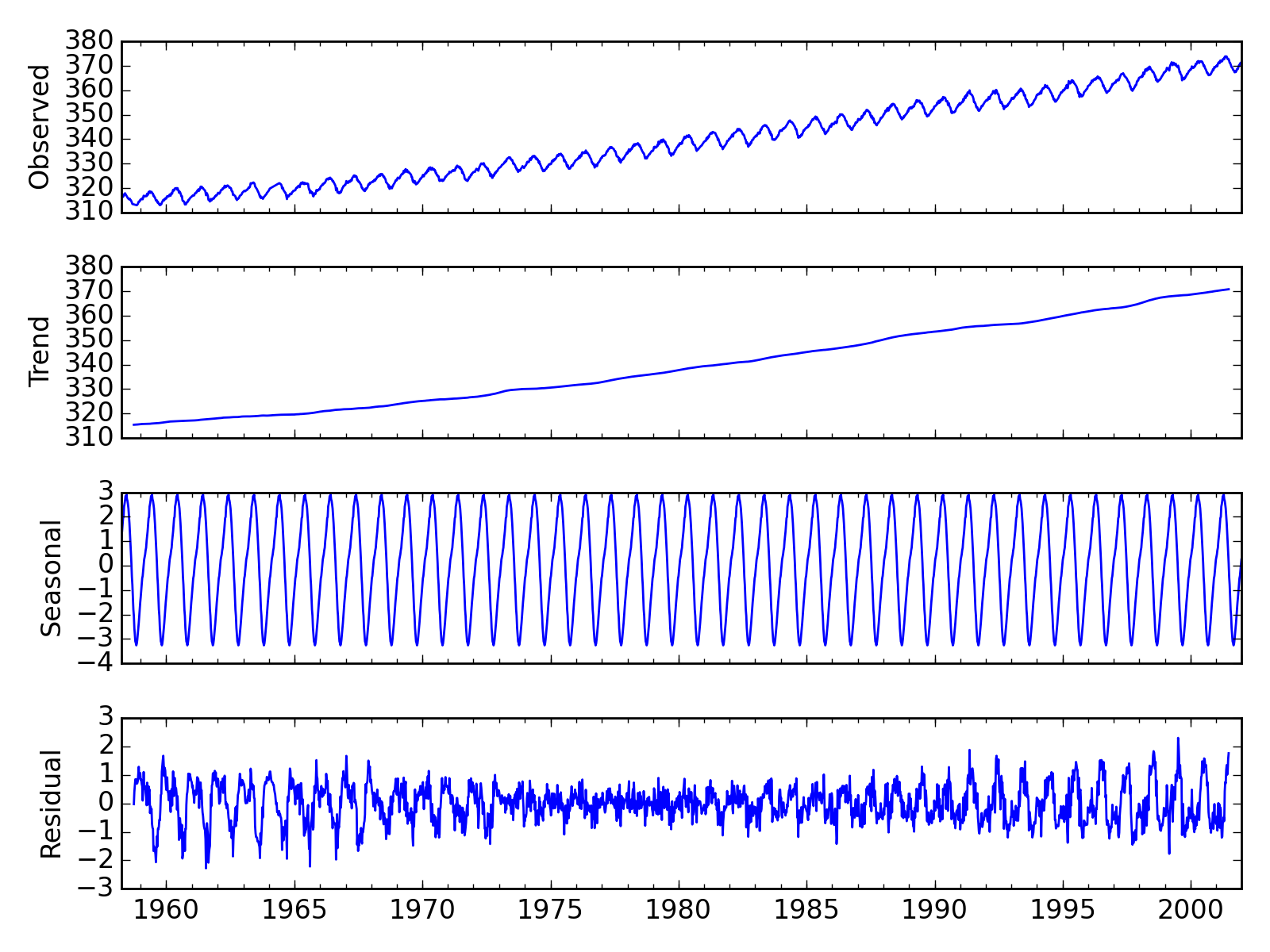
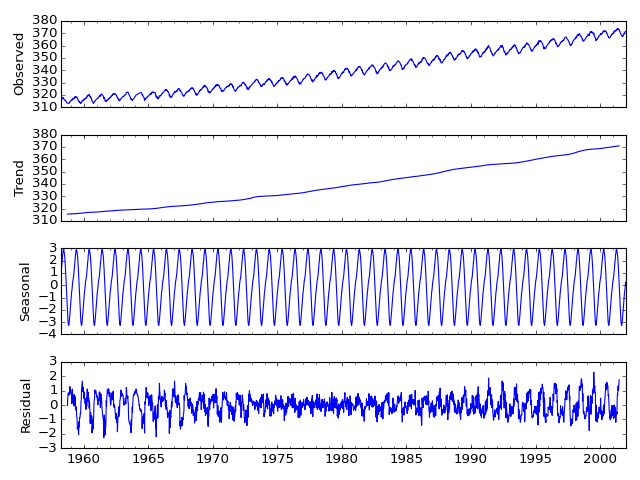
Seasonal Decomposition¶
We added a naive seasonal decomposition tool in the same vein as R’s decompose. This function can be found as sm.tsa.seasonal_decompose.
import statsmodels.api as sm
dta = sm.datasets.co2.load_pandas().data
# deal with missing values. see issue
dta.co2.interpolate(inplace=True)
res = sm.tsa.seasonal_decompose(dta.co2)
res.plot()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Addition of Linear Mixed Effects Models (MixedLM)
Linear Mixed Effects Models¶
Linear Mixed Effects models are used for regression analyses involving dependent data. Such data arise when working with longitudinal and other study designs in which multiple observations are made on each subject. Two specific mixed effects models are “random intercepts models”, where all responses in a single group are additively shifted by a value that is specific to the group, and “random slopes models”, where the values follow a mean trajectory that is linear in observed covariates, with both the slopes and intercept being specific to the group. The Statsmodels MixedLM implementation allows arbitrary random effects design matrices to be specified for the groups, so these and other types of random effects models can all be fit.
Here is an example of fitting a random intercepts model to data from a longitudinal study:
import statsmodels.api as sm
import statsmodels.formula.api as smf
data = sm.datasets.get_rdataset('dietox', 'geepack', cache=True).data
md = smf.mixedlm("Weight ~ Time", data, groups=data["Pig"])
mdf = md.fit()
print mdf.summary()
The Statsmodels LME framework currently supports post-estimation inference via Wald tests and confidence intervals on the coefficients, profile likelihood analysis, likelihood ratio testing, and AIC. Some limitations of the current implementation are that it does not support structure more complex on the residual errors (they are always homoscedastic), and it does not support crossed random effects. We hope to implement these features for the next release.
Wrapping X-12-ARIMA/X-13-ARIMA¶
It is now possible to call out to X-12-ARIMA or X-13ARIMA-SEATS from statsmodels. These libraries must be installed separately.
import statsmodels.api as sm
dta = sm.datasets.co2.load_pandas().data
dta.co2.interpolate(inplace=True)
dta = dta.resample('M')
res = sm.tsa.x13_arima_select_order(dta.co2)
print(res.order, res.sorder)
results = sm.tsa.x13_arima_analysis(dta.co2)
fig = results.plot()
fig.set_size_inches(12, 5)
fig.tight_layout()
Other important new features¶
- The AR(I)MA models now have a
plot_predictmethod to plot forecasts and confidence intervals. - The Kalman filter Cython code underlying AR(I)MA estimation has been substantially optimized. You can expect speed-ups of one to two orders of magnitude.
- Added
sm.tsa.arma_order_select_ic. A convenience function to quickly get the information criteria for use in tentative order selection of ARMA processes. - Plotting functions for timeseries is now imported under the
sm.tsa.graphicsnamespace in addition tosm.graphics.tsa. - New distributions.ExpandedNormal class implements the Edgeworth expansion for weakly non-normal distributions.
- New datasets: Added new datasets for examples.
sm.datasets.co2is a univariate time-series dataset of weekly co2 readings. It exhibits a trend and seasonality and has missing values. - Added robust skewness and kurtosis estimators in
sm.stats.stattools.robust_skewnessandsm.stats.stattools.robust_kurtosis, respectively. An alternative robust measure of skewness has been added insm.stats.stattools.medcouple. - New functions added to correlation tools: corr_nearest_factor finds the closest factor-structured correlation matrix to a given square matrix in the Frobenius norm; corr_thresholded efficiently constructs a hard-thresholded correlation matrix using sparse matrix operations.
- New dot_plot in graphics: A dotplot is a way to visualize a small dataset in a way that immediately conveys the identity of every point in the plot. Dotplots are commonly seen in meta-analyses, where they are known as “forest plots”, but can be used in many other settings as well. Most tables that appear in research papers can be represented graphically as a dotplot.
- Statsmodels has added custom warnings to
statsmodels.tools.sm_exceptions. By default all of these warnings will be raised whenever appropriate. Usewarnings.simplefilterto turn them off, if desired. - Allow control over the namespace used to evaluate formulas with patsy via the
eval_envkeyword argument. See the Namespaces documentation for more information.
Major Bugs fixed¶
Backwards incompatible changes and deprecations¶
- RegressionResults.norm_resid is now a readonly property, rather than a function.
- The function
statsmodels.tsa.filters.arfilterhas been removed. This did not compute a recursive AR filter but was instead a convolution filter. Two new functions have been added with clearer namessm.tsa.filters.recursive_filterandsm.tsa.filters.convolution_filter.
Development summary and credits¶
The previous version (0.5.0) was released August 14, 2014. Since then we have closed a total of 528 issues, 276 pull requests, and 252 regular issues. Refer to the detailed list for more information.
This release is a result of the work of the following 37 authors who contributed a total of 1531 commits. If for any reason we have failed to list your name in the below, please contact us:
A blurb about the number of changes and the contributors list.
- Alex Griffing <argriffi-at-ncsu.edu>
- Alex Parij <paris.alex-at-gmail.com>
- Ana Martinez Pardo <anamartinezpardo-at-gmail.com>
- Andrew Clegg <andrewclegg-at-users.noreply.github.com>
- Ben Duffield <bduffield-at-palantir.com>
- Chad Fulton <chad-at-chadfulton.com>
- Chris Kerr <cjk34-at-cam.ac.uk>
- Eric Chiang <eric.chiang.m-at-gmail.com>
- Evgeni Burovski <evgeni-at-burovski.me>
- gliptak <gliptak-at-gmail.com>
- Hans-Martin von Gaudecker <hmgaudecker-at-uni-bonn.de>
- Jan Schulz <jasc-at-gmx.net>
- jfoo <jcjf1983-at-gmail.com>
- Joe Hand <joe.a.hand-at-gmail.com>
- Josef Perktold <josef.pktd-at-gmail.com>
- jsphon <jonathanhon-at-hotmail.com>
- Justin Grana <jg3705a-at-student.american.edu>
- Kerby Shedden <kshedden-at-umich.edu>
- Kevin Sheppard <kevin.sheppard-at-economics.ox.ac.uk>
- Kyle Beauchamp <kyleabeauchamp-at-gmail.com>
- Lars Buitinck <l.buitinck-at-esciencecenter.nl>
- Max Linke <max_linke-at-gmx.de>
- Miroslav Batchkarov <mbatchkarov-at-gmail.com>
- m <mngu2382-at-gmail.com>
- Padarn Wilson <padarn-at-gmail.com>
- Paul Hobson <pmhobson-at-gmail.com>
- Pietro Battiston <me-at-pietrobattiston.it>
- Radim Řehůřek <radimrehurek-at-seznam.cz>
- Ralf Gommers <ralf.gommers-at-googlemail.com>
- Richard T. Guy <richardtguy84-at-gmail.com>
- Roy Hyunjin Han <rhh-at-crosscompute.com>
- Skipper Seabold <jsseabold-at-gmail.com>
- Tom Augspurger <thomas-augspurger-at-uiowa.edu>
- Trent Hauck <trent.hauck-at-gmail.com>
- Valentin Haenel <valentin.haenel-at-gmx.de>
- Vincent Arel-Bundock <varel-at-umich.edu>
- Yaroslav Halchenko <debian-at-onerussian.com>
Note
Obtained by running git log v0.5.0..HEAD --format='* %aN <%aE>' | sed 's/@/\-at\-/' | sed 's/<>//' | sort -u.