
statsmodels.regression.linear_model.OLS.fit_regularized¶
-
OLS.fit_regularized(method='elastic_net', alpha=0.0, L1_wt=1.0, start_params=None, profile_scale=False, refit=False, **kwargs)[source]¶ Return a regularized fit to a linear regression model.
Parameters: method : string
Only the ‘elastic_net’ approach is currently implemented.
alpha : scalar or array-like
The penalty weight. If a scalar, the same penalty weight applies to all variables in the model. If a vector, it must have the same length as params, and contains a penalty weight for each coefficient.
L1_wt: scalar
The fraction of the penalty given to the L1 penalty term. Must be between 0 and 1 (inclusive). If 0, the fit is a ridge fit, if 1 it is a lasso fit.
start_params : array-like
Starting values for
params.profile_scale : bool
If True the penalized fit is computed using the profile (concentrated) log-likelihood for the Gaussian model. Otherwise the fit uses the residual sum of squares.
refit : bool
If True, the model is refit using only the variables that have non-zero coefficients in the regularized fit. The refitted model is not regularized.
Returns: An array of coefficients, or a RegressionResults object of the
same type returned by
fit.Notes
The elastic net approach closely follows that implemented in the glmnet package in R. The penalty is a combination of L1 and L2 penalties.
The function that is minimized is: ..math:
0.5*RSS/n + alpha*((1-L1_wt)*|params|_2^2/2 + L1_wt*|params|_1)
where RSS is the usual regression sum of squares, n is the sample size, and
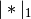 and
and 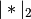 are the L1 and L2
norms.
are the L1 and L2
norms.Post-estimation results are based on the same data used to select variables, hence may be subject to overfitting biases.
The elastic_net method uses the following keyword arguments:
- maxiter : int
- Maximum number of iterations
- cnvrg_tol : float
- Convergence threshold for line searches
- zero_tol : float
- Coefficients below this threshold are treated as zero.
References
Friedman, Hastie, Tibshirani (2008). Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software 33(1), 1-22 Feb 2010.