Prediction (out of sample)#
[1]:
%matplotlib inline
[2]:
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm
plt.rc("figure", figsize=(16, 8))
plt.rc("font", size=14)
Artificial data#
[3]:
nsample = 50
sig = 0.25
x1 = np.linspace(0, 20, nsample)
X = np.column_stack((x1, np.sin(x1), (x1 - 5) ** 2))
X = sm.add_constant(X)
beta = [5.0, 0.5, 0.5, -0.02]
y_true = np.dot(X, beta)
y = y_true + sig * np.random.normal(size=nsample)
Estimation#
[4]:
olsmod = sm.OLS(y, X)
olsres = olsmod.fit()
print(olsres.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.983
Model: OLS Adj. R-squared: 0.982
Method: Least Squares F-statistic: 894.0
Date: Tue, 28 Jul 2026 Prob (F-statistic): 9.03e-41
Time: 19:10:57 Log-Likelihood: -0.23108
No. Observations: 50 AIC: 8.462
Df Residuals: 46 BIC: 16.11
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 5.0407 0.086 58.353 0.000 4.867 5.215
x1 0.4891 0.013 36.710 0.000 0.462 0.516
x2 0.4342 0.052 8.292 0.000 0.329 0.540
x3 -0.0184 0.001 -15.750 0.000 -0.021 -0.016
==============================================================================
Omnibus: 1.577 Durbin-Watson: 2.091
Prob(Omnibus): 0.455 Jarque-Bera (JB): 1.528
Skew: -0.338 Prob(JB): 0.466
Kurtosis: 2.474 Cond. No. 221.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
In-sample prediction#
[5]:
ypred = olsres.predict(X)
print(ypred)
[ 4.5801088 5.02422186 5.43387734 5.785409 6.06369163 6.26462606
6.39581265 6.47530259 6.52863212 6.58462698 6.67066647 6.80818507
7.00915084 7.27409908 7.59204439 7.94228555 8.29780666 8.62971578
8.91199181 9.12575963 9.2623913 9.32492356 9.32755891 9.2933322
9.25032602 9.22705688 9.24778997 9.32855248 9.47450038 9.67907132
9.92506276 10.18745836 10.43753804 10.64759665 10.79549583 10.86830125
10.86440775 10.79380301 10.67642662 10.53889405 10.41012383 10.3165863
10.27795461 10.30387245 10.39236969 10.53018599 10.69494948 10.85885238
10.99321976 11.0732207 ]
Create a new sample of explanatory variables Xnew, predict and plot#
[6]:
x1n = np.linspace(20.5, 25, 10)
Xnew = np.column_stack((x1n, np.sin(x1n), (x1n - 5) ** 2))
Xnew = sm.add_constant(Xnew)
ynewpred = olsres.predict(Xnew) # predict out of sample
print(ynewpred)
[11.07322273 10.95803053 10.74467373 10.47196073 10.19097702 9.95257769
9.79493631 9.73419874 9.76053004 9.84052241]
Plot comparison#
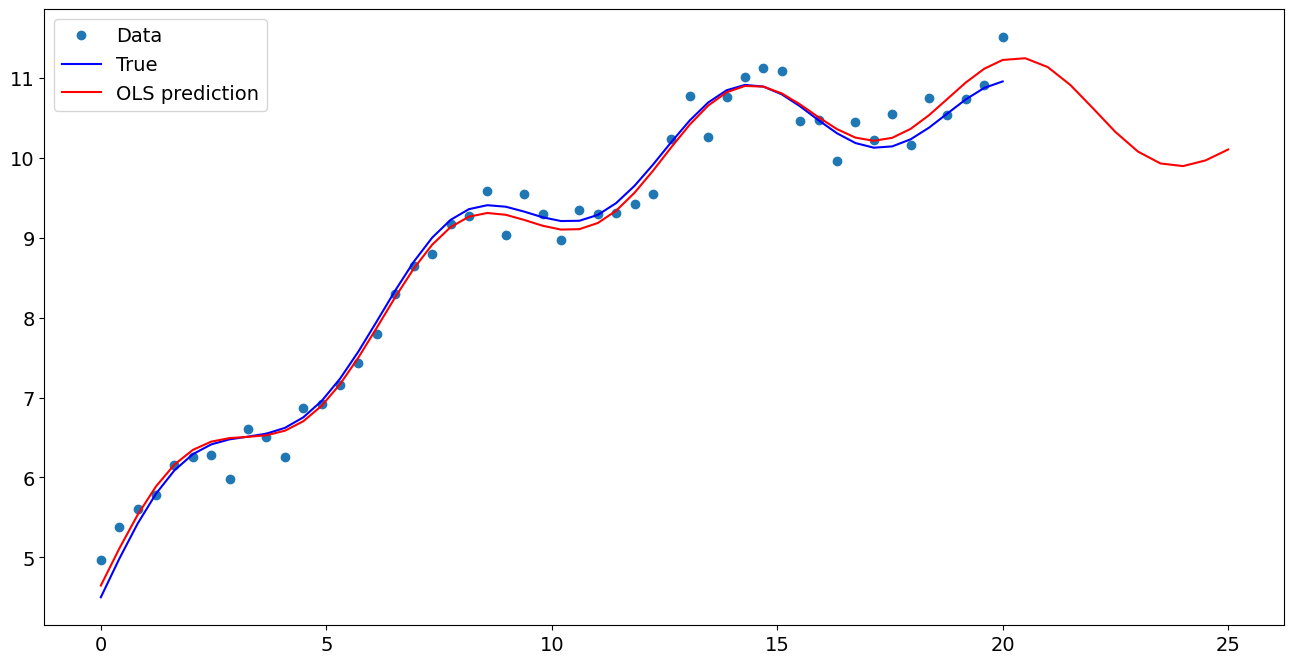
[7]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot(x1, y, "o", label="Data")
ax.plot(x1, y_true, "b-", label="True")
ax.plot(np.hstack((x1, x1n)), np.hstack((ypred, ynewpred)), "r", label="OLS prediction")
ax.legend(loc="best")
[7]:
<matplotlib.legend.Legend at 0x7fed7512aba0>
Predicting with Formulas#
Using formulas can make both estimation and prediction a lot easier
[8]:
from statsmodels.formula.api import ols
data = {"x1": x1, "y": y}
res = ols("y ~ x1 + np.sin(x1) + I((x1-5)**2)", data=data).fit()
We use the I to indicate use of the Identity transform. Ie., we do not want any expansion magic from using **2
[9]:
res.params
[9]:
Intercept 5.040698
x1 0.489069
np.sin(x1) 0.434250
I((x1 - 5) ** 2) -0.018424
dtype: float64
Now we only have to pass the single variable and we get the transformed right-hand side variables automatically
[10]:
res.predict(exog=dict(x1=x1n))
[10]:
0 11.073223
1 10.958031
2 10.744674
3 10.471961
4 10.190977
5 9.952578
6 9.794936
7 9.734199
8 9.760530
9 9.840522
dtype: float64