Prediction (out of sample)#
[1]:
%matplotlib inline
[2]:
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm
plt.rc("figure", figsize=(16, 8))
plt.rc("font", size=14)
Artificial data#
[3]:
nsample = 50
sig = 0.25
x1 = np.linspace(0, 20, nsample)
X = np.column_stack((x1, np.sin(x1), (x1 - 5) ** 2))
X = sm.add_constant(X)
beta = [5.0, 0.5, 0.5, -0.02]
y_true = np.dot(X, beta)
y = y_true + sig * np.random.normal(size=nsample)
Estimation#
[4]:
olsmod = sm.OLS(y, X)
olsres = olsmod.fit()
print(olsres.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.981
Model: OLS Adj. R-squared: 0.980
Method: Least Squares F-statistic: 789.4
Date: Thu, 30 Jul 2026 Prob (F-statistic): 1.50e-39
Time: 06:42:34 Log-Likelihood: -2.5586
No. Observations: 50 AIC: 13.12
Df Residuals: 46 BIC: 20.77
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 4.9861 0.090 55.095 0.000 4.804 5.168
x1 0.4970 0.014 35.610 0.000 0.469 0.525
x2 0.4856 0.055 8.851 0.000 0.375 0.596
x3 -0.0200 0.001 -16.322 0.000 -0.022 -0.018
==============================================================================
Omnibus: 0.352 Durbin-Watson: 2.042
Prob(Omnibus): 0.839 Jarque-Bera (JB): 0.361
Skew: -0.184 Prob(JB): 0.835
Kurtosis: 2.805 Cond. No. 221.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
In-sample prediction#
[5]:
ypred = olsres.predict(X)
print(ypred)
[ 4.48605912 4.95999909 5.39560386 5.76640624 6.05549094 6.25827363
6.38325421 6.45062024 6.48893022 6.5304215 6.60571376 6.73877829
6.9429996 7.21897634 7.55442296 7.92618823 8.30405885 8.65572346
8.95208131 9.17202339 9.3059006 9.3571091 9.34153229 9.28493121
9.21871212 9.17476649 9.18023134 9.25303074 9.39893086 9.61059266
9.86877769 10.14550884 10.40866697 10.62726797 10.77655335 10.84205799
10.82198675 10.72750936 10.58092532 10.41200009 10.25307476 10.13375248
10.07603476 10.09070666 10.17556485 10.31577963 10.48633136 10.65612116
10.79308034 10.86943923]
Create a new sample of explanatory variables Xnew, predict and plot#
[6]:
x1n = np.linspace(20.5, 25, 10)
Xnew = np.column_stack((x1n, np.sin(x1n), (x1n - 5) ** 2))
Xnew = sm.add_constant(Xnew)
ynewpred = olsres.predict(Xnew) # predict out of sample
print(ynewpred)
[10.85365462 10.70934319 10.45555009 10.13567675 9.80685472 9.52595791
9.33567781 9.25407117 9.27013906 9.34651979]
Plot comparison#
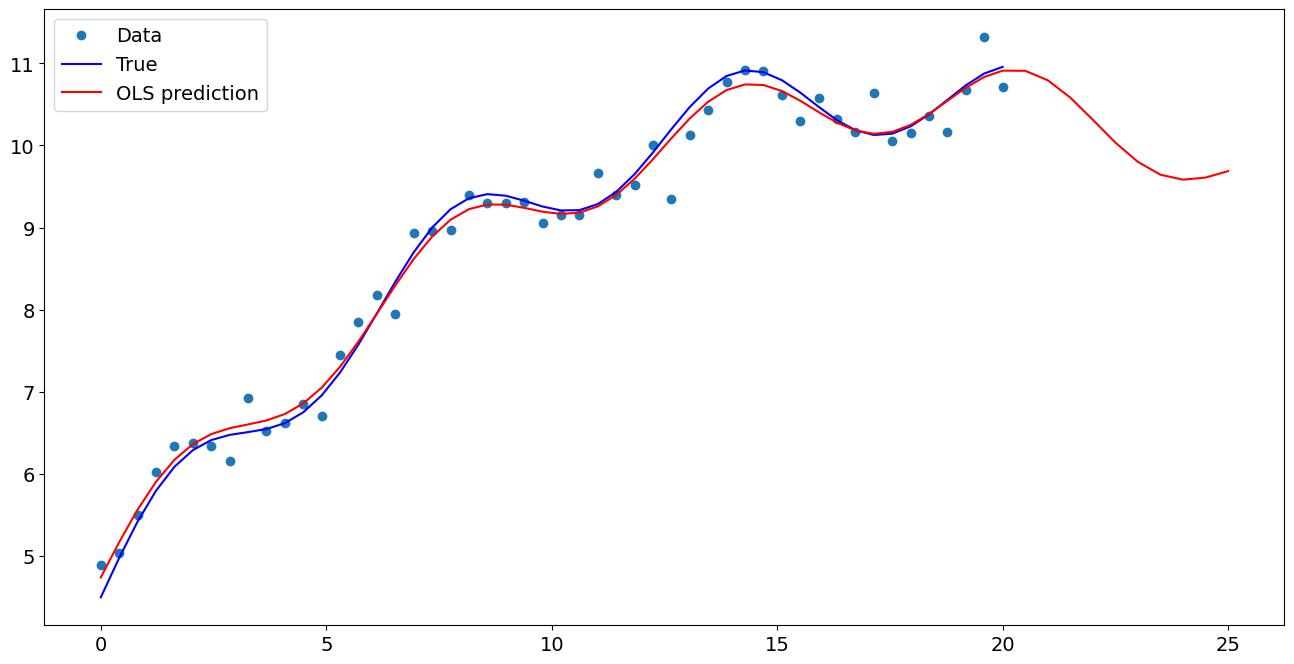
[7]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot(x1, y, "o", label="Data")
ax.plot(x1, y_true, "b-", label="True")
ax.plot(np.hstack((x1, x1n)), np.hstack((ypred, ynewpred)), "r", label="OLS prediction")
ax.legend(loc="best")
[7]:
<matplotlib.legend.Legend at 0x7f28e966aba0>
Predicting with Formulas#
Using formulas can make both estimation and prediction a lot easier
[8]:
from statsmodels.formula.api import ols
data = {"x1": x1, "y": y}
res = ols("y ~ x1 + np.sin(x1) + I((x1-5)**2)", data=data).fit()
We use the I to indicate use of the Identity transform. Ie., we do not want any expansion magic from using **2
[9]:
res.params
[9]:
Intercept 4.986115
x1 0.497023
np.sin(x1) 0.485644
I((x1 - 5) ** 2) -0.020002
dtype: float64
Now we only have to pass the single variable and we get the transformed right-hand side variables automatically
[10]:
res.predict(exog=dict(x1=x1n))
[10]:
0 10.853655
1 10.709343
2 10.455550
3 10.135677
4 9.806855
5 9.525958
6 9.335678
7 9.254071
8 9.270139
9 9.346520
dtype: float64