Custom statespace models#
The true power of the state space model is to allow the creation and estimation of custom models. This notebook shows various statespace models that subclass sm.tsa.statespace.MLEModel.
Remember the general state space model can be written in the following general way:
You can check the details and the dimensions of the objects in this link
Most models won’t include all of these elements. For example, the design matrix \(Z_t\) might not depend on time (\(\forall t \;Z_t = Z\)), or the model won’t have an observation intercept \(d_t\).
We’ll start with something relatively simple and then show how to extend it bit by bit to include more elements.
Model 1: time-varying coefficients. One observation equation with two state equations
Model 2: time-varying parameters with non identity transition matrix
Model 3: multiple observation and multiple state equations
Bonus: PyMC for Bayesian estimation
[1]:
%matplotlib inline
from collections import OrderedDict
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import statsmodels.api as sm
plt.rc("figure", figsize=(16, 8))
plt.rc("font", size=15)
Model 1: time-varying coefficients#
The observed data is \(y_t, x_t, w_t\). With \(x_t, w_t\) being the exogenous variables. Notice that the design matrix is time-varying, so it will have three dimensions (k_endog x k_states x nobs)
The states are \(\beta_{x,t}\) and \(\beta_{w,t}\). The state equation tells us these states evolve with a random walk. Thus, in this case the transition matrix is a 2 by 2 identity matrix.
We’ll first simulate the data, the construct a model and finally estimate it.
[2]:
def gen_data_for_model1():
nobs = 1000
rs = np.random.RandomState(seed=93572)
d = 5
var_y = 5
var_coeff_x = 0.01
var_coeff_w = 0.5
x_t = rs.uniform(size=nobs)
w_t = rs.uniform(size=nobs)
eps = rs.normal(scale=var_y**0.5, size=nobs)
beta_x = np.cumsum(rs.normal(size=nobs, scale=var_coeff_x**0.5))
beta_w = np.cumsum(rs.normal(size=nobs, scale=var_coeff_w**0.5))
y_t = d + beta_x * x_t + beta_w * w_t + eps
return y_t, x_t, w_t, beta_x, beta_w
y_t, x_t, w_t, beta_x, beta_w = gen_data_for_model1()
_ = plt.plot(y_t)
[3]:
class TVRegression(sm.tsa.statespace.MLEModel):
def __init__(self, y_t, x_t, w_t):
exog = np.c_[x_t, w_t] # shaped nobs x 2
super().__init__(endog=y_t, exog=exog, k_states=2, initialization="diffuse")
# Since the design matrix is time-varying, it must be
# shaped k_endog x k_states x nobs
# Notice that exog.T is shaped k_states x nobs, so we
# just need to add a new first axis with shape 1
self.ssm["design"] = exog.T[np.newaxis, :, :] # shaped 1 x 2 x nobs
self.ssm["selection"] = np.eye(self.k_states)
self.ssm["transition"] = np.eye(self.k_states)
# Which parameters need to be positive?
self.positive_parameters = slice(1, 4)
@property
def param_names(self):
return ["intercept", "var.e", "var.x.coeff", "var.w.coeff"]
@property
def start_params(self):
"""
Defines the starting values for the parameters
The linear regression gives us reasonable starting values for the constant
d and the variance of the epsilon error
"""
exog = sm.add_constant(self.exog)
res = sm.OLS(self.endog, exog).fit()
params = np.r_[res.params[0], res.scale, 0.001, 0.001]
return params
def transform_params(self, unconstrained):
"""
We constraint the last three parameters
('var.e', 'var.x.coeff', 'var.w.coeff') to be positive,
because they are variances
"""
constrained = unconstrained.copy()
constrained[self.positive_parameters] = (
constrained[self.positive_parameters] ** 2
)
return constrained
def untransform_params(self, constrained):
"""
Need to unstransform all the parameters you transformed
in the `transform_params` function
"""
unconstrained = constrained.copy()
unconstrained[self.positive_parameters] = (
unconstrained[self.positive_parameters] ** 0.5
)
return unconstrained
def update(self, params, **kwargs):
params = super().update(params, **kwargs)
self["obs_intercept", 0, 0] = params[0]
self["obs_cov", 0, 0] = params[1]
self["state_cov"] = np.diag(params[2:4])
And then estimate it with our custom model class#
[4]:
mod = TVRegression(y_t, x_t, w_t)
res = mod.fit()
print(res.summary())
Statespace Model Results
==============================================================================
Dep. Variable: y No. Observations: 1000
Model: TVRegression Log Likelihood -2336.846
Date: Wed, 29 Jul 2026 AIC 4685.692
Time: 17:23:35 BIC 4715.139
Sample: 0 HQIC 4696.884
- 1000
Covariance Type: opg
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
intercept 5.0548 0.202 25.050 0.000 4.659 5.450
var.e 5.1240 0.249 20.571 0.000 4.636 5.612
var.x.coeff 0.0468 0.022 2.097 0.036 0.003 0.091
var.w.coeff 0.4092 0.096 4.243 0.000 0.220 0.598
===================================================================================
Ljung-Box (L1) (Q): 0.08 Jarque-Bera (JB): 0.98
Prob(Q): 0.78 Prob(JB): 0.61
Heteroskedasticity (H): 1.05 Skew: 0.07
Prob(H) (two-sided): 0.63 Kurtosis: 2.93
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
The values that generated the data were:
intercept = 5
var.e = 5
var.x.coeff = 0.01
var.w.coeff = 0.5
As you can see, the estimation recovered the real parameters pretty well.
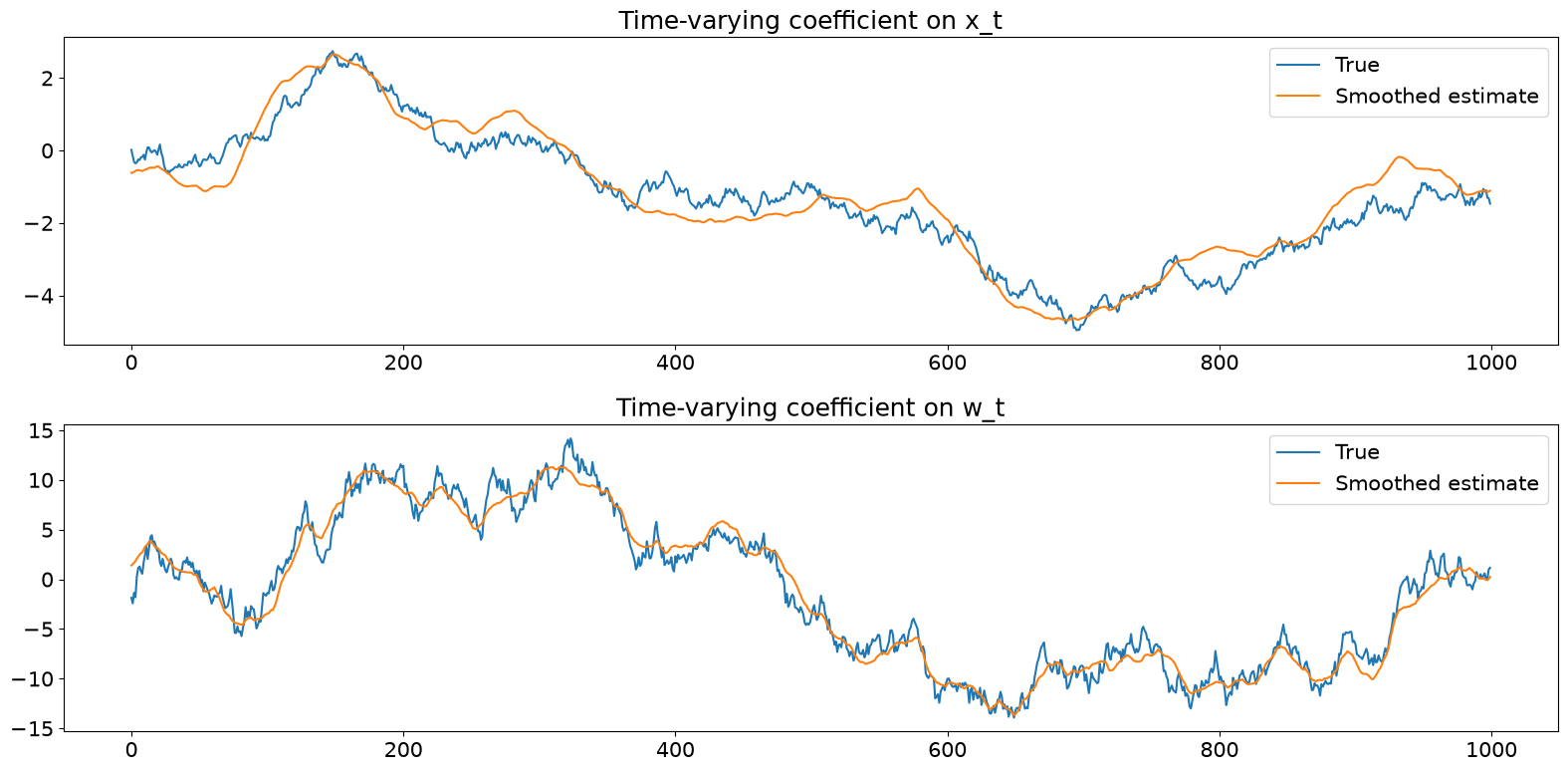
We can also recover the estimated evolution of the underlying coefficients (or states in Kalman filter talk)
[5]:
fig, axes = plt.subplots(2, figsize=(16, 8))
ss = pd.DataFrame(res.smoothed_state.T, columns=["x", "w"])
axes[0].plot(beta_x, label="True")
axes[0].plot(ss["x"], label="Smoothed estimate")
axes[0].set(title="Time-varying coefficient on x_t")
axes[0].legend()
axes[1].plot(beta_w, label="True")
axes[1].plot(ss["w"], label="Smoothed estimate")
axes[1].set(title="Time-varying coefficient on w_t")
axes[1].legend()
fig.tight_layout();
Model 2: time-varying parameters with non identity transition matrix#
This is a small extension from Model 1. Instead of having an identity transition matrix, we’ll have one with two parameters (\(\rho_1, \rho_2\)) that we need to estimate.
What should we modify in our previous class to make things work?
Good news: not a lot!
Bad news: we need to be careful about a few things
1) Change the starting parameters function#
We need to add names for the new parameters \(\rho_1, \rho_2\) and we need to start corresponding starting values.
The param_names function goes from:
def param_names(self):
return ['intercept', 'var.e', 'var.x.coeff', 'var.w.coeff']
to
def param_names(self):
return ['intercept', 'var.e', 'var.x.coeff', 'var.w.coeff',
'rho1', 'rho2']
and we change the start_params function from
def start_params(self):
exog = sm.add_constant(self.exog)
res = sm.OLS(self.endog, exog).fit()
params = np.r_[res.params[0], res.scale, 0.001, 0.001]
return params
to
def start_params(self):
exog = sm.add_constant(self.exog)
res = sm.OLS(self.endog, exog).fit()
params = np.r_[res.params[0], res.scale, 0.001, 0.001, 0.8, 0.8]
return params
Change the
updatefunction
It goes from
def update(self, params, **kwargs):
params = super(TVRegression, self).update(params, **kwargs)
self['obs_intercept', 0, 0] = params[0]
self['obs_cov', 0, 0] = params[1]
self['state_cov'] = np.diag(params[2:4])
to
def update(self, params, **kwargs):
params = super(TVRegression, self).update(params, **kwargs)
self['obs_intercept', 0, 0] = params[0]
self['obs_cov', 0, 0] = params[1]
self['state_cov'] = np.diag(params[2:4])
self['transition', 0, 0] = params[4]
self['transition', 1, 1] = params[5]
(optional) change
transform_paramsanduntransform_params
This is not required, but you might wanna restrict \(\rho_1, \rho_2\) to lie between -1 and 1. In that case, we first import two utility functions from statsmodels.
from statsmodels.tsa.statespace.tools import (
constrain_stationary_univariate, unconstrain_stationary_univariate)
constrain_stationary_univariate constraint the value to be within -1 and 1. unconstrain_stationary_univariate provides the inverse function. The transform and untransform parameters function would look like this (remember that \(\rho_1, \rho_2\) are in the 4 and 5th index):
def transform_params(self, unconstrained):
constrained = unconstrained.copy()
constrained[self.positive_parameters] = constrained[self.positive_parameters]**2
constrained[4] = constrain_stationary_univariate(constrained[4:5])
constrained[5] = constrain_stationary_univariate(constrained[5:6])
return constrained
def untransform_params(self, constrained):
unconstrained = constrained.copy()
unconstrained[self.positive_parameters] = unconstrained[self.positive_parameters]**0.5
unconstrained[4] = unconstrain_stationary_univariate(constrained[4:5])
unconstrained[5] = unconstrain_stationary_univariate(constrained[5:6])
return unconstrained
I’ll write the full class below (without the optional changes I have just discussed)
[6]:
class TVRegressionExtended(sm.tsa.statespace.MLEModel):
def __init__(self, y_t, x_t, w_t):
exog = np.c_[x_t, w_t] # shaped nobs x 2
super().__init__(endog=y_t, exog=exog, k_states=2, initialization="diffuse")
# Since the design matrix is time-varying, it must be
# shaped k_endog x k_states x nobs
# Notice that exog.T is shaped k_states x nobs, so we
# just need to add a new first axis with shape 1
self.ssm["design"] = exog.T[np.newaxis, :, :] # shaped 1 x 2 x nobs
self.ssm["selection"] = np.eye(self.k_states)
self.ssm["transition"] = np.eye(self.k_states)
# Which parameters need to be positive?
self.positive_parameters = slice(1, 4)
@property
def param_names(self):
return ["intercept", "var.e", "var.x.coeff", "var.w.coeff", "rho1", "rho2"]
@property
def start_params(self):
"""
Defines the starting values for the parameters
The linear regression gives us reasonable starting values for the constant
d and the variance of the epsilon error
"""
exog = sm.add_constant(self.exog)
res = sm.OLS(self.endog, exog).fit()
params = np.r_[res.params[0], res.scale, 0.001, 0.001, 0.7, 0.8]
return params
def transform_params(self, unconstrained):
"""
We constraint the last three parameters
('var.e', 'var.x.coeff', 'var.w.coeff') to be positive,
because they are variances
"""
constrained = unconstrained.copy()
constrained[self.positive_parameters] = (
constrained[self.positive_parameters] ** 2
)
return constrained
def untransform_params(self, constrained):
"""
Need to unstransform all the parameters you transformed
in the `transform_params` function
"""
unconstrained = constrained.copy()
unconstrained[self.positive_parameters] = (
unconstrained[self.positive_parameters] ** 0.5
)
return unconstrained
def update(self, params, **kwargs):
params = super().update(params, **kwargs)
self["obs_intercept", 0, 0] = params[0]
self["obs_cov", 0, 0] = params[1]
self["state_cov"] = np.diag(params[2:4])
self["transition", 0, 0] = params[4]
self["transition", 1, 1] = params[5]
To estimate, we’ll use the same data as in model 1 and expect the \(\rho_1, \rho_2\) to be near 1.
The results look pretty good! Note that this estimation can be quite sensitive to the starting value of \(\rho_1, \rho_2\). If you try lower values, you’ll see it fails to converge.
[7]:
mod = TVRegressionExtended(y_t, x_t, w_t)
res = mod.fit(maxiter=2000) # it doesn't converge with 50 iters
print(res.summary())
Statespace Model Results
================================================================================
Dep. Variable: y No. Observations: 1000
Model: TVRegressionExtended Log Likelihood -2334.778
Date: Wed, 29 Jul 2026 AIC 4685.557
Time: 17:23:41 BIC 4724.819
Sample: 0 HQIC 4700.479
- 1000
Covariance Type: opg
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
intercept 5.0316 0.201 25.077 0.000 4.638 5.425
var.e 5.1000 0.249 20.460 0.000 4.611 5.589
var.x.coeff 0.0599 0.033 1.806 0.071 -0.005 0.125
var.w.coeff 0.4237 0.104 4.068 0.000 0.220 0.628
rho1 0.9946 0.004 237.820 0.000 0.986 1.003
rho2 0.9964 0.003 336.981 0.000 0.991 1.002
===================================================================================
Ljung-Box (L1) (Q): 0.15 Jarque-Bera (JB): 0.76
Prob(Q): 0.70 Prob(JB): 0.68
Heteroskedasticity (H): 1.05 Skew: 0.06
Prob(H) (two-sided): 0.64 Kurtosis: 2.95
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Model 3: multiple observation and state equations#
We’ll keep the time-varying parameters, but this time we’ll also have two observation equations.
Observation equations#
\(\hat{i_t}, \hat{M_t}, \hat{s_t}\) are observed each period.
The model for the observation equation has two equations:
Following the general notation from state space models, the endogenous part of the observation equation is \(y_t = (\hat{i_t}, \hat{M_t})\) and we only have one exogenous variable \(\hat{s_t}\)
State equations#
Matrix notation for the state space model#
I’ll simulate some data, talk about what we need to modify and finally estimate the model to see if we’re recovering something reasonable.
[8]:
true_values = {
"var_e1": 0.01,
"var_e2": 0.01,
"var_w1": 0.01,
"var_w2": 0.01,
"delta1": 0.8,
"delta2": 0.5,
"delta3": 0.7,
}
def gen_data_for_model3():
# Starting values
alpha1_0 = 2.1
alpha2_0 = 1.1
t_max = 500
def gen_i(alpha1, s):
return alpha1 * s + np.sqrt(true_values["var_e1"]) * np.random.randn()
def gen_m_hat(alpha2):
return 1 * alpha2 + np.sqrt(true_values["var_e2"]) * np.random.randn()
def gen_alpha1(alpha1, alpha2):
w1 = np.sqrt(true_values["var_w1"]) * np.random.randn()
return true_values["delta1"] * alpha1 + true_values["delta2"] * alpha2 + w1
def gen_alpha2(alpha2):
w2 = np.sqrt(true_values["var_w2"]) * np.random.randn()
return true_values["delta3"] * alpha2 + w2
s_t = 0.3 + np.sqrt(1.4) * np.random.randn(t_max)
i_hat = np.empty(t_max)
m_hat = np.empty(t_max)
current_alpha1 = alpha1_0
current_alpha2 = alpha2_0
for t in range(t_max):
# Obs eqns
i_hat[t] = gen_i(current_alpha1, s_t[t])
m_hat[t] = gen_m_hat(current_alpha2)
# state eqns
new_alpha1 = gen_alpha1(current_alpha1, current_alpha2)
new_alpha2 = gen_alpha2(current_alpha2)
# Update states for next period
current_alpha1 = new_alpha1
current_alpha2 = new_alpha2
return i_hat, m_hat, s_t
i_hat, m_hat, s_t = gen_data_for_model3()
What do we need to modify?#
Once again, we don’t need to change much, but we need to be careful about the dimensions.
1) The __init__ function changes from#
def __init__(self, y_t, x_t, w_t):
exog = np.c_[x_t, w_t]
super(TVRegressionExtended, self).__init__(
endog=y_t, exog=exog, k_states=2,
initialization='diffuse')
self.ssm['design'] = exog.T[np.newaxis, :, :] # shaped 1 x 2 x nobs
self.ssm['selection'] = np.eye(self.k_states)
self.ssm['transition'] = np.eye(self.k_states)
to
def __init__(self, i_t: np.array, s_t: np.array, m_t: np.array):
exog = np.c_[s_t, np.repeat(1, len(s_t))] # exog.shape => (nobs, 2)
super(MultipleYsModel, self).__init__(
endog=np.c_[i_t, m_t], exog=exog, k_states=2,
initialization='diffuse')
self.ssm['design'] = np.zeros((self.k_endog, self.k_states, self.nobs))
self.ssm['design', 0, 0, :] = s_t
self.ssm['design', 1, 1, :] = 1
Note that we did not have to specify k_endog anywhere. The initialization does this for us after checking the dimensions of the endog matrix.
2) The update() function#
changes from
def update(self, params, **kwargs):
params = super(TVRegressionExtended, self).update(params, **kwargs)
self['obs_intercept', 0, 0] = params[0]
self['obs_cov', 0, 0] = params[1]
self['state_cov'] = np.diag(params[2:4])
self['transition', 0, 0] = params[4]
self['transition', 1, 1] = params[5]
to
def update(self, params, **kwargs):
params = super(MultipleYsModel, self).update(params, **kwargs)
#The following line is not needed (by default, this matrix is initialized by zeroes),
#But I leave it here so the dimensions are clearer
self['obs_intercept'] = np.repeat([np.array([0, 0])], self.nobs, axis=0).T
self['obs_cov', 0, 0] = params[0]
self['obs_cov', 1, 1] = params[1]
self['state_cov'] = np.diag(params[2:4])
#delta1, delta2, delta3
self['transition', 0, 0] = params[4]
self['transition', 0, 1] = params[5]
self['transition', 1, 1] = params[6]
The rest of the methods change in pretty obvious ways (need to add parameter names, make sure the indexes work, etc). The full code for the function is right below
[9]:
starting_values = {
"var_e1": 0.2,
"var_e2": 0.1,
"var_w1": 0.15,
"var_w2": 0.18,
"delta1": 0.7,
"delta2": 0.1,
"delta3": 0.85,
}
class MultipleYsModel(sm.tsa.statespace.MLEModel):
def __init__(self, i_t: np.array, s_t: np.array, m_t: np.array):
exog = np.c_[s_t, np.repeat(1, len(s_t))] # exog.shape => (nobs, 2)
super().__init__(
endog=np.c_[i_t, m_t], exog=exog, k_states=2, initialization="diffuse"
)
self.ssm["design"] = np.zeros((self.k_endog, self.k_states, self.nobs))
self.ssm["design", 0, 0, :] = s_t
self.ssm["design", 1, 1, :] = 1
# These have ok shape. Placeholders since I'm changing them
# in the update() function
self.ssm["selection"] = np.eye(self.k_states)
self.ssm["transition"] = np.eye(self.k_states)
# Dictionary of positions to names
self.position_dict = OrderedDict(
var_e1=1, var_e2=2, var_w1=3, var_w2=4, delta1=5, delta2=6, delta3=7
)
self.initial_values = starting_values
self.positive_parameters = slice(0, 4)
@property
def param_names(self):
return list(self.position_dict.keys())
@property
def start_params(self):
"""
Initial values
"""
# (optional) Use scale for var_e1 and var_e2 starting values
params = np.r_[
self.initial_values["var_e1"],
self.initial_values["var_e2"],
self.initial_values["var_w1"],
self.initial_values["var_w2"],
self.initial_values["delta1"],
self.initial_values["delta2"],
self.initial_values["delta3"],
]
return params
def transform_params(self, unconstrained):
"""
If you need to restrict parameters
For example, variances should be > 0
Parameters maybe have to be within -1 and 1
"""
constrained = unconstrained.copy()
constrained[self.positive_parameters] = (
constrained[self.positive_parameters] ** 2
)
return constrained
def untransform_params(self, constrained):
"""
Need to reverse what you did in transform_params()
"""
unconstrained = constrained.copy()
unconstrained[self.positive_parameters] = (
unconstrained[self.positive_parameters] ** 0.5
)
return unconstrained
def update(self, params, **kwargs):
params = super().update(params, **kwargs)
# The following line is not needed (by default, this matrix is initialized by zeroes),
# But I leave it here so the dimensions are clearer
self["obs_intercept"] = np.repeat([np.array([0, 0])], self.nobs, axis=0).T
self["obs_cov", 0, 0] = params[0]
self["obs_cov", 1, 1] = params[1]
self["state_cov"] = np.diag(params[2:4])
# delta1, delta2, delta3
self["transition", 0, 0] = params[4]
self["transition", 0, 1] = params[5]
self["transition", 1, 1] = params[6]
[10]:
mod = MultipleYsModel(i_hat, s_t, m_hat)
res = mod.fit()
print(res.summary())
Statespace Model Results
==============================================================================
Dep. Variable: ['y1', 'y2'] No. Observations: 500
Model: MultipleYsModel Log Likelihood 475.703
Date: Wed, 29 Jul 2026 AIC -933.406
Time: 17:23:43 BIC -895.474
Sample: 0 HQIC -918.522
- 500
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
var_e1 0.0082 0.001 9.176 0.000 0.006 0.010
var_e2 0.0097 0.002 5.689 0.000 0.006 0.013
var_w1 0.0099 0.001 7.448 0.000 0.007 0.013
var_w2 0.0105 0.002 5.184 0.000 0.007 0.014
delta1 0.8006 0.023 35.265 0.000 0.756 0.845
delta2 0.5114 0.066 7.763 0.000 0.382 0.641
delta3 0.6940 0.046 15.095 0.000 0.604 0.784
===================================================================================
Ljung-Box (L1) (Q): 0.10, 0.05 Jarque-Bera (JB): 0.78, 1.29
Prob(Q): 0.76, 0.82 Prob(JB): 0.68, 0.53
Heteroskedasticity (H): 1.25, 0.97 Skew: 0.02, 0.10
Prob(H) (two-sided): 0.15, 0.83 Kurtosis: 3.19, 2.85
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Bonus: PyMC for fast Bayesian estimation#
In this section I’ll show how you can take your custom state space model and easily plug it into PyMC and estimate it with Bayesian methods. In particular, this example will show you an estimation with a version of Hamiltonian Monte Carlo called the No-U-Turn Sampler (NUTS).
I’m basically copying the ideas contained in this notebook, so make sure to check that for more details.
[11]:
# Extra requirements
import pymc as pm
from pytensor.graph.op import Op
import pytensor.tensor as pt
We need to define some helper functions to connect PyTensor to the likelihood function that is implied in our model
[12]:
class Loglike(Op):
itypes = [pt.dvector] # expects a vector of parameter values when called
otypes = [pt.dscalar] # outputs a single scalar value (the log likelihood)
def __init__(self, model):
self.model = model
self.score = Score(self.model)
def perform(self, node, inputs, outputs):
(theta,) = inputs # contains the vector of parameters
llf = self.model.loglike(theta)
outputs[0][0] = np.array(llf) # output the log-likelihood
def grad(self, inputs, g):
# the method that calculates the gradients - it actually returns the
# vector-Jacobian product - g[0] is a vector of parameter values
(theta,) = inputs # our parameters
out = [g[0] * self.score(theta)]
return out
class Score(Op):
itypes = [pt.dvector]
otypes = [pt.dvector]
def __init__(self, model):
self.model = model
def perform(self, node, inputs, outputs):
(theta,) = inputs
outputs[0][0] = self.model.score(theta)
We’ll simulate again the data we used for model 1. We’ll also fit it again and save the results to compare them to the Bayesian posterior we get.
[13]:
y_t, x_t, w_t, beta_x, beta_w = gen_data_for_model1()
plt.plot(y_t)
[13]:
[<matplotlib.lines.Line2D at 0x7fc93f2e4050>]
[14]:
mod = TVRegression(y_t, x_t, w_t)
res_mle = mod.fit(disp=False)
print(res_mle.summary())
Statespace Model Results
==============================================================================
Dep. Variable: y No. Observations: 1000
Model: TVRegression Log Likelihood -2336.846
Date: Wed, 29 Jul 2026 AIC 4685.692
Time: 17:23:45 BIC 4715.139
Sample: 0 HQIC 4696.884
- 1000
Covariance Type: opg
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
intercept 5.0548 0.202 25.050 0.000 4.659 5.450
var.e 5.1240 0.249 20.571 0.000 4.636 5.612
var.x.coeff 0.0468 0.022 2.097 0.036 0.003 0.091
var.w.coeff 0.4092 0.096 4.243 0.000 0.220 0.598
===================================================================================
Ljung-Box (L1) (Q): 0.08 Jarque-Bera (JB): 0.98
Prob(Q): 0.78 Prob(JB): 0.61
Heteroskedasticity (H): 1.05 Skew: 0.07
Prob(H) (two-sided): 0.63 Kurtosis: 2.93
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Bayesian estimation#
We need to define a prior for each parameter and the number of draws and burn-in points
[15]:
# Set sampling params
ndraws = 3000 # 3000 number of draws from the distribution
nburn = 600 # 600 number of "burn-in points" (which will be discarded)
[16]:
# Construct an instance of the PyTensor wrapper defined above, which
# will allow PyMC to compute the likelihood and Jacobian in a way
# that it can make use of. Here we are using the same model instance
# created earlier for MLE analysis (we could also create a new model
# instance if we preferred)
loglike = Loglike(mod)
with pm.Model():
# Priors
intercept = pm.Uniform("intercept", 1, 10)
var_e = pm.InverseGamma("var.e", 2.3, 0.5)
var_x_coeff = pm.InverseGamma("var.x.coeff", 2.3, 0.1)
var_w_coeff = pm.InverseGamma("var.w.coeff", 2.3, 0.1)
# convert variables to tensor vectors
theta = pt.as_tensor_variable([intercept, var_e, var_x_coeff, var_w_coeff])
# use a Potential to add the statsmodels log-likelihood to the model
pm.Potential("likelihood", loglike(theta))
# Draw samples
trace = pm.sample(
ndraws,
tune=nburn,
cores=1,
compute_convergence_checks=False,
)
/opt/hostedtoolcache/Python/3.14.6/x64/lib/python3.14/site-packages/pytensor/gradient.py:1327: FutureWarning: Loglike should implement `pullback` instead of `L_op`/`grad`. Direct `L_op`/`grad` implementations are deprecated and will stop being called in a future version.
input_grads = node.op.pullback(inputs, node.outputs, new_output_grads)
Initializing NUTS using jitter+adapt_diag...
/opt/hostedtoolcache/Python/3.14.6/x64/lib/python3.14/site-packages/pytensor/gradient.py:1327: FutureWarning: Loglike should implement `pullback` instead of `L_op`/`grad`. Direct `L_op`/`grad` implementations are deprecated and will stop being called in a future version.
input_grads = node.op.pullback(inputs, node.outputs, new_output_grads)
/opt/hostedtoolcache/Python/3.14.6/x64/lib/python3.14/site-packages/pytensor/link/numba/dispatch/basic.py:234: UserWarning: Numba will use object mode to run Loglike's perform method. Set `pytensor.config.compiler_verbose = True` to see more details.
warnings.warn(
/opt/hostedtoolcache/Python/3.14.6/x64/lib/python3.14/site-packages/pytensor/link/numba/dispatch/basic.py:234: UserWarning: Numba will use object mode to run Score's perform method. Set `pytensor.config.compiler_verbose = True` to see more details.
warnings.warn(
Sequential sampling (2 chains in 1 job)
NUTS: [intercept, var.e, var.x.coeff, var.w.coeff]
How does the posterior distribution compare with the MLE estimation?#
The clearly peak around the MLE estimate.
[ ]:
_ = pm.plot_trace(trace)