SARIMAX: Model selection, missing data#
The example mirrors Durbin and Koopman (2012), Chapter 8.4 in application of Box-Jenkins methodology to fit ARMA models. The novel feature is the ability of the model to work on datasets with missing values.
[1]:
%matplotlib inline
[2]:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import statsmodels.api as sm
[3]:
# Download the dataset
df = pd.read_table(
"https://raw.githubusercontent.com/jrnold/ssmodels-in-stan/master/StanStateSpace/data-raw/DK-data/internet.dat",
skiprows=1,
header=None,
sep=r"\s+",
engine="python",
names=["internet", "dinternet"],
)
Model Selection#
As in Durbin and Koopman, we force a number of the values to be missing.
[4]:
# Get the basic series
dta_full = df.dinternet[1:].values
dta_miss = dta_full.copy()
# Remove datapoints
missing = np.r_[6, 16, 26, 36, 46, 56, 66, 72, 73, 74, 75, 76, 86, 96] - 1
dta_miss[missing] = np.nan
Then we can consider model selection using the Akaike information criteria (AIC), but running the model for each variant and selecting the model with the lowest AIC value.
There are a couple of things to note here:
When running such a large batch of models, particularly when the autoregressive and moving average orders become large, there is the possibility of poor maximum likelihood convergence. Below we ignore the warnings since this example is illustrative.
We use the option
enforce_invertibility=False, which allows the moving average polynomial to be non-invertible, so that more of the models are estimable.Several of the models do not produce good results, and their AIC value is set to NaN. This is not surprising, as Durbin and Koopman note numerical problems with the high order models.
[5]:
import warnings
aic_full = pd.DataFrame(np.zeros((6, 6), dtype=float))
aic_miss = pd.DataFrame(np.zeros((6, 6), dtype=float))
warnings.simplefilter("ignore")
# Iterate over all ARMA(p,q) models with p,q in [0,6]
for p in range(6):
for q in range(6):
if p == 0 and q == 0:
continue
# Estimate the model with no missing datapoints
mod = sm.tsa.statespace.SARIMAX(
dta_full, order=(p, 0, q), enforce_invertibility=False
)
try:
res = mod.fit(disp=False)
aic_full.iloc[p, q] = res.aic
except Exception:
aic_full.iloc[p, q] = np.nan
# Estimate the model with missing datapoints
mod = sm.tsa.statespace.SARIMAX(
dta_miss, order=(p, 0, q), enforce_invertibility=False
)
try:
res = mod.fit(disp=False)
aic_miss.iloc[p, q] = res.aic
except Exception:
aic_miss.iloc[p, q] = np.nan
For the models estimated over the full (non-missing) dataset, the AIC chooses ARMA(1,1) or ARMA(3,0). Durbin and Koopman suggest the ARMA(1,1) specification is better due to parsimony.
For the models estimated over missing dataset, the AIC chooses ARMA(1,1)
Note: the AIC values are calculated differently than in Durbin and Koopman, but show overall similar trends.
Postestimation#
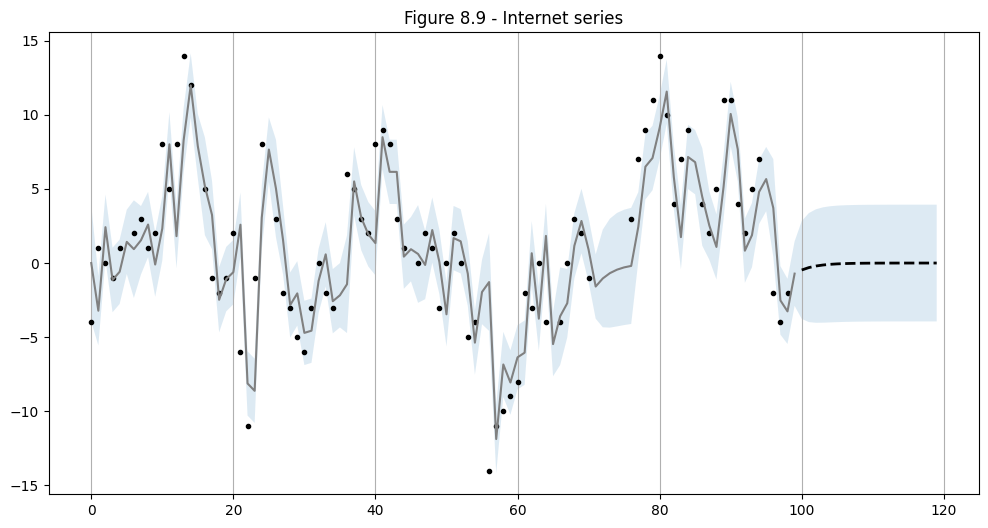
Using the ARMA(1,1) specification selected above, we perform in-sample prediction and out-of-sample forecasting.
[6]:
# Statespace
mod = sm.tsa.statespace.SARIMAX(dta_miss, order=(1, 0, 1))
res = mod.fit(disp=False)
print(res.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 99
Model: SARIMAX(1, 0, 1) Log Likelihood -225.770
Date: Wed, 29 Jul 2026 AIC 457.541
Time: 17:33:59 BIC 465.326
Sample: 0 HQIC 460.691
- 99
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.6562 0.092 7.125 0.000 0.476 0.837
ma.L1 0.4878 0.111 4.390 0.000 0.270 0.706
sigma2 10.3402 1.569 6.591 0.000 7.265 13.415
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 1.87
Prob(Q): 0.96 Prob(JB): 0.39
Heteroskedasticity (H): 0.59 Skew: -0.10
Prob(H) (two-sided): 0.13 Kurtosis: 3.64
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[7]:
# In-sample one-step-ahead predictions, and out-of-sample forecasts
nforecast = 20
predict = res.get_prediction(end=mod.nobs + nforecast)
idx = np.arange(len(predict.predicted_mean))
predict_ci = predict.conf_int(alpha=0.5)
# Graph
fig, ax = plt.subplots(figsize=(12, 6))
ax.xaxis.grid()
ax.plot(dta_miss, "k.")
# Plot
ax.plot(idx[:-nforecast], predict.predicted_mean[:-nforecast], "gray")
ax.plot(
idx[-nforecast:],
predict.predicted_mean[-nforecast:],
"k--",
linestyle="--",
linewidth=2,
)
ax.fill_between(idx, predict_ci[:, 0], predict_ci[:, 1], alpha=0.15)
ax.set(title="Figure 8.9 - Internet series");